import starsim as ss
ss.options(jupyter=True)
import numpy as np
import pandas as pd
from pathlib import Path
import matplotlib.pyplot as plt
import sciris as scSamples
As Starsim models are usually stochastic, for a single scenario it is often desirable to run the model multiple times with different random seeds. The role of the Samples class is to facilitate working with large numbers of simulations and scenarios, to ease:
- Loading large result sets
- Filtering/selecting simulation runs
- Plotting individual simulations and aggregate results
- Slicing result sets to compare scenarios
Essentially, if we think of the processed results of a model run as being
- A collection of scalar outputs (e.g., cumulative infections, total deaths)
- A dataframe of time-varying outputs (e.g., new diagnoses per day, number of people on treatment each day)
then the classes Dataset and Samples manage collections of these results. In particular, the Samples class manages different random samples of the same parameters, and the Dataset class manages a collection of Samples.
These classes are particularly designed to facilitate working with tens of thousands of simulation runs, where other approaches such as those based on the MultiSim class may not be feasible.
Obtaining simulation output
To demonstrate usage of this class, we will first consider constructing the kinds of output that the Samples class stores. We begin by running a basic simulation using the SIR model:
ppl = ss.People(5000)
net = ss.ndict(ss.RandomNet(n_contacts=ss.poisson(5)))
sir = ss.SIR()
sim = ss.Sim(people=ppl, networks=net, diseases=sir, rand_seed=0)
sim.run();Initializing sim with 5000 agents
Running 2000 ( 0/51) (0.00 s) ———————————————————— 2%
Running 2010 (10/51) (0.05 s) ••••———————————————— 22%
Running 2020 (20/51) (0.08 s) ••••••••———————————— 41%
Running 2030 (30/51) (0.11 s) ••••••••••••———————— 61%
Running 2040 (40/51) (0.14 s) ••••••••••••••••———— 80%
Running 2050 (50/51) (0.17 s) •••••••••••••••••••• 100%
Dataframe output
A Sim instance is (in general) too large and complex to efficiently store on disk - the file size and loading time make it prohibitive to work with tens of thousands of simulations. Therefore, rather than storing entire Sim instances, we instead store dataframes containing just the simulation results and any other pre-processed calculated quantities. There are broadly speaking two types of outputs:
- Scalar outputs at each timepoint (e.g., daily new cases)
- Scalar outputs for each simulation (e.g., total number of deaths)
These outputs can each be produced from a Sim - the former has a tabular structure, and the latter has a dictionary structure (which can later be assembled into a table where the rows correspond to each simulation). The export_df method is a quick way to obtain a dataframe with the appropriate structure retaining all results from the Sim.
In real-world use, it is often helpful to write your own function to extract a dataframe of simulation outputs, because typically some of the outputs need to be extracted from custom Analyzers.
sim.to_df()| timevec | randomnet_n_edges | sir_n_susceptible | sir_n_infected | sir_n_recovered | sir_prevalence | sir_new_infections | sir_cum_infections | n_alive | n_female | new_deaths | new_emigrants | cum_deaths | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2000-01-01 | 12575.0 | 4899.0 | 101.0 | 0.0 | 0.020200 | 41.0 | 41.0 | 5000.0 | 2465.0 | 0.0 | 0.0 | 0.0 |
| 1 | 2001-01-01 | 12478.0 | 4854.0 | 146.0 | 0.0 | 0.029200 | 45.0 | 86.0 | 5000.0 | 2465.0 | 0.0 | 0.0 | 0.0 |
| 2 | 2002-01-01 | 12667.0 | 4784.0 | 216.0 | 0.0 | 0.043200 | 70.0 | 156.0 | 5000.0 | 2465.0 | 0.0 | 0.0 | 0.0 |
| 3 | 2003-01-01 | 12440.0 | 4692.0 | 308.0 | 0.0 | 0.061600 | 92.0 | 248.0 | 5000.0 | 2465.0 | 0.0 | 0.0 | 0.0 |
| 4 | 2004-01-01 | 12285.0 | 4562.0 | 438.0 | 0.0 | 0.087600 | 130.0 | 378.0 | 5000.0 | 2465.0 | 0.0 | 0.0 | 0.0 |
| 5 | 2005-01-01 | 12428.0 | 4386.0 | 605.0 | 9.0 | 0.121000 | 176.0 | 554.0 | 5000.0 | 2465.0 | 0.0 | 0.0 | 0.0 |
| 6 | 2006-01-01 | 12547.0 | 4170.0 | 766.0 | 63.0 | 0.153200 | 216.0 | 770.0 | 4999.0 | 2465.0 | 1.0 | 0.0 | 0.0 |
| 7 | 2007-01-01 | 12397.0 | 3873.0 | 1010.0 | 116.0 | 0.202040 | 297.0 | 1067.0 | 4999.0 | 2465.0 | 0.0 | 0.0 | 1.0 |
| 8 | 2008-01-01 | 12435.0 | 3555.0 | 1264.0 | 180.0 | 0.252851 | 318.0 | 1385.0 | 4999.0 | 2465.0 | 0.0 | 0.0 | 1.0 |
| 9 | 2009-01-01 | 12360.0 | 3177.0 | 1556.0 | 266.0 | 0.311262 | 378.0 | 1763.0 | 4999.0 | 2465.0 | 0.0 | 0.0 | 1.0 |
| 10 | 2010-01-01 | 12507.0 | 2765.0 | 1847.0 | 387.0 | 0.369474 | 412.0 | 2175.0 | 4999.0 | 2465.0 | 0.0 | 0.0 | 1.0 |
| 11 | 2011-01-01 | 12387.0 | 2361.0 | 2089.0 | 545.0 | 0.417884 | 404.0 | 2579.0 | 4995.0 | 2465.0 | 4.0 | 0.0 | 1.0 |
| 12 | 2012-01-01 | 12482.0 | 1991.0 | 2260.0 | 740.0 | 0.452452 | 370.0 | 2949.0 | 4991.0 | 2462.0 | 4.0 | 0.0 | 5.0 |
| 13 | 2013-01-01 | 12542.0 | 1651.0 | 2345.0 | 992.0 | 0.469846 | 340.0 | 3289.0 | 4988.0 | 2461.0 | 3.0 | 0.0 | 9.0 |
| 14 | 2014-01-01 | 12673.0 | 1350.0 | 2345.0 | 1289.0 | 0.470128 | 301.0 | 3590.0 | 4984.0 | 2458.0 | 4.0 | 0.0 | 12.0 |
| 15 | 2015-01-01 | 12472.0 | 1116.0 | 2225.0 | 1639.0 | 0.446429 | 234.0 | 3824.0 | 4980.0 | 2456.0 | 4.0 | 0.0 | 16.0 |
| 16 | 2016-01-01 | 12479.0 | 953.0 | 2023.0 | 2003.0 | 0.406225 | 163.0 | 3987.0 | 4979.0 | 2453.0 | 1.0 | 0.0 | 20.0 |
| 17 | 2017-01-01 | 12236.0 | 793.0 | 1776.0 | 2407.0 | 0.356698 | 160.0 | 4147.0 | 4976.0 | 2452.0 | 3.0 | 0.0 | 21.0 |
| 18 | 2018-01-01 | 12351.0 | 706.0 | 1487.0 | 2779.0 | 0.298834 | 87.0 | 4234.0 | 4972.0 | 2450.0 | 4.0 | 0.0 | 24.0 |
| 19 | 2019-01-01 | 12547.0 | 636.0 | 1199.0 | 3135.0 | 0.241150 | 70.0 | 4304.0 | 4970.0 | 2447.0 | 2.0 | 0.0 | 28.0 |
| 20 | 2020-01-01 | 12449.0 | 577.0 | 936.0 | 3453.0 | 0.188330 | 59.0 | 4363.0 | 4966.0 | 2445.0 | 4.0 | 0.0 | 30.0 |
| 21 | 2021-01-01 | 12436.0 | 537.0 | 712.0 | 3715.0 | 0.143375 | 40.0 | 4403.0 | 4964.0 | 2443.0 | 2.0 | 0.0 | 34.0 |
| 22 | 2022-01-01 | 12369.0 | 508.0 | 550.0 | 3905.0 | 0.110798 | 29.0 | 4432.0 | 4963.0 | 2441.0 | 1.0 | 0.0 | 36.0 |
| 23 | 2023-01-01 | 12436.0 | 484.0 | 405.0 | 4074.0 | 0.081604 | 24.0 | 4456.0 | 4963.0 | 2441.0 | 0.0 | 0.0 | 37.0 |
| 24 | 2024-01-01 | 12422.0 | 473.0 | 297.0 | 4192.0 | 0.059843 | 11.0 | 4467.0 | 4962.0 | 2441.0 | 1.0 | 0.0 | 37.0 |
| 25 | 2025-01-01 | 12424.0 | 465.0 | 217.0 | 4280.0 | 0.043732 | 8.0 | 4475.0 | 4962.0 | 2440.0 | 0.0 | 0.0 | 38.0 |
| 26 | 2026-01-01 | 12440.0 | 462.0 | 155.0 | 4345.0 | 0.031237 | 3.0 | 4478.0 | 4962.0 | 2440.0 | 0.0 | 0.0 | 38.0 |
| 27 | 2027-01-01 | 12385.0 | 461.0 | 103.0 | 4397.0 | 0.020758 | 1.0 | 4479.0 | 4961.0 | 2440.0 | 1.0 | 0.0 | 38.0 |
| 28 | 2028-01-01 | 12311.0 | 459.0 | 70.0 | 4432.0 | 0.014110 | 2.0 | 4481.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 29 | 2029-01-01 | 12438.0 | 457.0 | 50.0 | 4454.0 | 0.010079 | 2.0 | 4483.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 30 | 2030-01-01 | 12556.0 | 457.0 | 24.0 | 4480.0 | 0.004838 | 0.0 | 4483.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 31 | 2031-01-01 | 12382.0 | 455.0 | 17.0 | 4489.0 | 0.003427 | 2.0 | 4485.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 32 | 2032-01-01 | 12441.0 | 454.0 | 11.0 | 4496.0 | 0.002217 | 1.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 33 | 2033-01-01 | 12393.0 | 454.0 | 8.0 | 4499.0 | 0.001613 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 34 | 2034-01-01 | 12465.0 | 454.0 | 5.0 | 4502.0 | 0.001008 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 35 | 2035-01-01 | 12477.0 | 454.0 | 3.0 | 4504.0 | 0.000605 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 36 | 2036-01-01 | 12448.0 | 454.0 | 3.0 | 4504.0 | 0.000605 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 37 | 2037-01-01 | 12469.0 | 454.0 | 3.0 | 4504.0 | 0.000605 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 38 | 2038-01-01 | 12476.0 | 454.0 | 1.0 | 4506.0 | 0.000202 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 39 | 2039-01-01 | 12363.0 | 454.0 | 1.0 | 4506.0 | 0.000202 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 40 | 2040-01-01 | 12359.0 | 454.0 | 1.0 | 4506.0 | 0.000202 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 41 | 2041-01-01 | 12308.0 | 454.0 | 0.0 | 4507.0 | 0.000000 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 42 | 2042-01-01 | 12369.0 | 454.0 | 0.0 | 4507.0 | 0.000000 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 43 | 2043-01-01 | 12429.0 | 454.0 | 0.0 | 4507.0 | 0.000000 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 44 | 2044-01-01 | 12338.0 | 454.0 | 0.0 | 4507.0 | 0.000000 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 45 | 2045-01-01 | 12289.0 | 454.0 | 0.0 | 4507.0 | 0.000000 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 46 | 2046-01-01 | 12384.0 | 454.0 | 0.0 | 4507.0 | 0.000000 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 47 | 2047-01-01 | 12430.0 | 454.0 | 0.0 | 4507.0 | 0.000000 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 48 | 2048-01-01 | 12315.0 | 454.0 | 0.0 | 4507.0 | 0.000000 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 49 | 2049-01-01 | 12508.0 | 454.0 | 0.0 | 4507.0 | 0.000000 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
| 50 | 2050-01-01 | 12420.0 | 454.0 | 0.0 | 4507.0 | 0.000000 | 0.0 | 4486.0 | 4961.0 | 2440.0 | 0.0 | 0.0 | 39.0 |
Scalar/summary outputs
We can also consider extracting a summary dictionary of scalar values. For example:
summary = {}
summary['seed'] = sim.pars['rand_seed']
summary['p_death'] = sim.diseases[0].pars.p_death.pars.p
summary['cum_infections'] = sum(sim.results.sir.new_infections)
summary['cum_deaths'] = sum(sim.results.new_deaths)
summary{'seed': 0, 'p_death': 0.01, 'cum_infections': 4486.0, 'cum_deaths': 39.0}
Notice how in the example above, the summary contains both simulation inputs (seed, probability of death) as well as simulation outputs (total infections, total deaths). The simulation summary should contain sufficient information about the simulation inputs to identify the simulation. The seed should generally be present. The other inputs normally correspond to variables that scenarios are being run over. In this example, we will run scenarios comparing simulations with different probabilities of death. Therefore, we need to include the death probability in the simulation summary.
Running the model
For usage at scale, the steps of creating a simulation, running it and producing these outputs are usually encapsulated in functions:
def get_sim(seed, p_death):
ppl = ss.People(2000)
net = ss.RandomNet(n_contacts=ss.poisson(5))
sir = ss.SIR(p_death=p_death)
sim = ss.Sim(people=ppl, networks=net, diseases=sir, rand_seed=seed)
sim.init(verbose=0)
return sim
def run_sim(seed, p_death):
sim = get_sim(seed, p_death)
sim.run(verbose=0)
df = sim.to_df()
summary = {}
summary['seed'] = sim.pars['rand_seed']
summary['p_death']= sim.diseases[0].pars.p_death.pars.p
summary['cum_infections'] = sum(sim.results.sir.new_infections)
summary['cum_deaths'] = sum(sim.results.new_deaths)
return df, summary
The functions above could be combined into a single function. However, in real world usage it is often convenient to be able to construct a simulation independently of running it (e.g., for diagnostic purposes or to allow running the sim in a range of different ways). The suggested structure above, with a
get_sim() function and a run_sim() function are recommended as standard practice.
Now running a simulation for a given beta/seed value and returning the processed outputs can be done in a single step:
# Scalar output
df, summary = run_sim(0, 0.2);
summary{'seed': 0, 'p_death': 0.2, 'cum_infections': 1841.0, 'cum_deaths': 367.0}We can produce all of the samples associated with a scenario by iterating over the input seed values. This is being done in a basic loop here, but could be done in more sophistical ways to leverage parallel computing (e.g., with sc.parallelize for single host parallelization, or with celery for distributed computation).
# Run a collection of sims
n = 20
seeds = np.arange(n)
outputs = [run_sim(seed, 0.2) for seed in seeds]Saving and loading the samples
We have now produced simulation outputs (dataframes and summary statistics) for 20 simulation runs. The outputs here are a list of tuples, containing the dataframe and dictionary outputs for each sample. This list can be passed to the cvv.Samples class to produce a single compressed file on disk:
resultsdir = Path('results')
resultsdir.mkdir(exist_ok=True, parents=True)
ss.Samples.new(outputs, identifiers=["p_death"], folder=resultsdir)
list(resultsdir.iterdir())Zip file saved to "/home/runner/work/starsim/starsim/docs/user_guide/results/0.2.zip"[PosixPath('results/0.2.zip')]Notice that a list of identifiers should be passed to the Samples constructor. This is a list of keys in the simulation summary dictionaries that identifies the scenario. These would be model inputs rather than model outputs, and they should be the same for all of the outputs passed into the Samples object. If no file name is explicitly provided, the file will automatically be assigned a name based on the identifiers.
The
Samples file internally contains metadata recording the identifiers. When Samples are accessed using the Dataset class, they can be accessed via the internal metadata. Therefore for a typical workflow, the file name largely doesn’t matter, and it usually doesn’t need to be manually specified.
The saved file can be loaded and accessed via the Samples class. Importantly, individual files can be extracted from a .zip file without decompressing the entire archive. This means that loading the summary dataframe and using it to selectively load the full outputs for individual runs can be done efficiently. For example, loading retrieving a single result from a Samples file would take a similar amount of time regardless of whether the file contained 10 samples or 100000 samples.
# Load the samples
res = ss.Samples('results/0.2.zip')
res.summary| cum_infections | cum_deaths | ||
|---|---|---|---|
| seed | p_death | ||
| 0 | 0.2 | 1841.0 | 367.0 |
| 1 | 0.2 | 1833.0 | 385.0 |
| 2 | 0.2 | 1856.0 | 382.0 |
| 3 | 0.2 | 1829.0 | 377.0 |
| 4 | 0.2 | 1862.0 | 418.0 |
| 5 | 0.2 | 1864.0 | 365.0 |
| 6 | 0.2 | 1853.0 | 393.0 |
| 7 | 0.2 | 1829.0 | 391.0 |
| 8 | 0.2 | 1829.0 | 374.0 |
| 9 | 0.2 | 1851.0 | 366.0 |
| 10 | 0.2 | 1823.0 | 362.0 |
| 11 | 0.2 | 1871.0 | 367.0 |
| 12 | 0.2 | 1868.0 | 384.0 |
| 13 | 0.2 | 1831.0 | 351.0 |
| 14 | 0.2 | 1822.0 | 334.0 |
| 15 | 0.2 | 1840.0 | 398.0 |
| 16 | 0.2 | 1834.0 | 355.0 |
| 17 | 0.2 | 1846.0 | 357.0 |
| 18 | 0.2 | 1818.0 | 356.0 |
| 19 | 0.2 | 1833.0 | 382.0 |
When the Samples file was created, a dictionary of scalars was provided for each result. These are automatically used to populate a ‘summary’ dataframe, where each identifier (and the seed) are used as the index, and the remaining keys appear as columns, as shown above. As a shortcut, columns of the summary dataframe can be accessed by indexing the Samples object directly, without having to access the .summary attribute e.g.,
res['cum_infections']seed p_death
0 0.2 1841.0
1 0.2 1833.0
2 0.2 1856.0
3 0.2 1829.0
4 0.2 1862.0
5 0.2 1864.0
6 0.2 1853.0
7 0.2 1829.0
8 0.2 1829.0
9 0.2 1851.0
10 0.2 1823.0
11 0.2 1871.0
12 0.2 1868.0
13 0.2 1831.0
14 0.2 1822.0
15 0.2 1840.0
16 0.2 1834.0
17 0.2 1846.0
18 0.2 1818.0
19 0.2 1833.0
Name: cum_infections, dtype: float64Each simulation is uniquely identified by its seed, and the time series dataframe for each simulation can be accessed by indexing the Samples object with the seed:
res[0]| Unnamed: 0 | randomnet_n_edges | sir_n_susceptible | sir_n_infected | sir_n_recovered | sir_prevalence | sir_new_infections | sir_cum_infections | n_alive | n_female | new_deaths | new_emigrants | cum_deaths | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| timevec | |||||||||||||
| 2000-01-01 | 0 | 5078.0 | 1977.0 | 23.0 | 0.0 | 0.011500 | 6.0 | 6.0 | 2000.0 | 996.0 | 0.0 | 0.0 | 0.0 |
| 2001-01-01 | 1 | 5008.0 | 1966.0 | 34.0 | 0.0 | 0.017000 | 11.0 | 17.0 | 2000.0 | 996.0 | 0.0 | 0.0 | 0.0 |
| 2002-01-01 | 2 | 5081.0 | 1946.0 | 54.0 | 0.0 | 0.027000 | 20.0 | 37.0 | 2000.0 | 996.0 | 0.0 | 0.0 | 0.0 |
| 2003-01-01 | 3 | 4907.0 | 1927.0 | 73.0 | 0.0 | 0.036500 | 19.0 | 56.0 | 2000.0 | 996.0 | 0.0 | 0.0 | 0.0 |
| 2004-01-01 | 4 | 4939.0 | 1885.0 | 115.0 | 0.0 | 0.057500 | 42.0 | 98.0 | 2000.0 | 996.0 | 0.0 | 0.0 | 0.0 |
| 2005-01-01 | 5 | 4954.0 | 1838.0 | 160.0 | 2.0 | 0.080000 | 47.0 | 145.0 | 2000.0 | 996.0 | 0.0 | 0.0 | 0.0 |
| 2006-01-01 | 6 | 5052.0 | 1780.0 | 205.0 | 15.0 | 0.102500 | 58.0 | 203.0 | 2000.0 | 996.0 | 0.0 | 0.0 | 0.0 |
| 2007-01-01 | 7 | 4958.0 | 1688.0 | 286.0 | 22.0 | 0.143000 | 92.0 | 295.0 | 1996.0 | 996.0 | 4.0 | 0.0 | 0.0 |
| 2008-01-01 | 8 | 4992.0 | 1592.0 | 367.0 | 35.0 | 0.183868 | 96.0 | 391.0 | 1994.0 | 994.0 | 2.0 | 0.0 | 4.0 |
| 2009-01-01 | 9 | 4947.0 | 1477.0 | 450.0 | 58.0 | 0.225677 | 115.0 | 506.0 | 1985.0 | 994.0 | 9.0 | 0.0 | 6.0 |
| 2010-01-01 | 10 | 4984.0 | 1329.0 | 570.0 | 83.0 | 0.287154 | 148.0 | 654.0 | 1982.0 | 992.0 | 3.0 | 0.0 | 15.0 |
| 2011-01-01 | 11 | 4893.0 | 1164.0 | 694.0 | 114.0 | 0.350151 | 165.0 | 819.0 | 1972.0 | 991.0 | 10.0 | 0.0 | 18.0 |
| 2012-01-01 | 12 | 4931.0 | 1008.0 | 788.0 | 166.0 | 0.399594 | 156.0 | 975.0 | 1962.0 | 987.0 | 10.0 | 0.0 | 28.0 |
| 2013-01-01 | 13 | 4977.0 | 829.0 | 888.0 | 234.0 | 0.452599 | 179.0 | 1154.0 | 1951.0 | 983.0 | 11.0 | 0.0 | 38.0 |
| 2014-01-01 | 14 | 4997.0 | 686.0 | 937.0 | 313.0 | 0.480267 | 143.0 | 1297.0 | 1936.0 | 979.0 | 15.0 | 0.0 | 49.0 |
| 2015-01-01 | 15 | 4874.0 | 539.0 | 984.0 | 396.0 | 0.508264 | 147.0 | 1444.0 | 1919.0 | 976.0 | 17.0 | 0.0 | 64.0 |
| 2016-01-01 | 16 | 4819.0 | 434.0 | 967.0 | 495.0 | 0.503908 | 105.0 | 1549.0 | 1896.0 | 969.0 | 23.0 | 0.0 | 81.0 |
| 2017-01-01 | 17 | 4698.0 | 352.0 | 896.0 | 618.0 | 0.472574 | 82.0 | 1631.0 | 1866.0 | 958.0 | 30.0 | 0.0 | 104.0 |
| 2018-01-01 | 18 | 4651.0 | 294.0 | 791.0 | 746.0 | 0.423901 | 58.0 | 1689.0 | 1831.0 | 939.0 | 35.0 | 0.0 | 134.0 |
| 2019-01-01 | 19 | 4633.0 | 245.0 | 683.0 | 876.0 | 0.373020 | 49.0 | 1738.0 | 1804.0 | 916.0 | 27.0 | 0.0 | 169.0 |
| 2020-01-01 | 20 | 4475.0 | 211.0 | 553.0 | 1000.0 | 0.306541 | 34.0 | 1772.0 | 1764.0 | 901.0 | 40.0 | 0.0 | 196.0 |
| 2021-01-01 | 21 | 4474.0 | 186.0 | 440.0 | 1109.0 | 0.249433 | 25.0 | 1797.0 | 1735.0 | 879.0 | 29.0 | 0.0 | 236.0 |
| 2022-01-01 | 22 | 4385.0 | 163.0 | 345.0 | 1201.0 | 0.198847 | 23.0 | 1820.0 | 1709.0 | 861.0 | 26.0 | 0.0 | 265.0 |
| 2023-01-01 | 23 | 4248.0 | 158.0 | 244.0 | 1289.0 | 0.142774 | 5.0 | 1825.0 | 1691.0 | 846.0 | 18.0 | 0.0 | 291.0 |
| 2024-01-01 | 24 | 4249.0 | 153.0 | 180.0 | 1342.0 | 0.106446 | 5.0 | 1830.0 | 1675.0 | 840.0 | 16.0 | 0.0 | 309.0 |
| 2025-01-01 | 25 | 4162.0 | 150.0 | 131.0 | 1383.0 | 0.078209 | 3.0 | 1833.0 | 1664.0 | 832.0 | 11.0 | 0.0 | 325.0 |
| 2026-01-01 | 26 | 4208.0 | 146.0 | 89.0 | 1422.0 | 0.053486 | 4.0 | 1837.0 | 1657.0 | 827.0 | 7.0 | 0.0 | 336.0 |
| 2027-01-01 | 27 | 4117.0 | 145.0 | 49.0 | 1452.0 | 0.029572 | 1.0 | 1838.0 | 1646.0 | 824.0 | 11.0 | 0.0 | 343.0 |
| 2028-01-01 | 28 | 4066.0 | 145.0 | 33.0 | 1463.0 | 0.020049 | 0.0 | 1838.0 | 1641.0 | 822.0 | 5.0 | 0.0 | 354.0 |
| 2029-01-01 | 29 | 4124.0 | 144.0 | 21.0 | 1474.0 | 0.012797 | 1.0 | 1839.0 | 1639.0 | 819.0 | 2.0 | 0.0 | 359.0 |
| 2030-01-01 | 30 | 4174.0 | 143.0 | 17.0 | 1479.0 | 0.010372 | 1.0 | 1840.0 | 1639.0 | 817.0 | 0.0 | 0.0 | 361.0 |
| 2031-01-01 | 31 | 4100.0 | 143.0 | 9.0 | 1485.0 | 0.005491 | 0.0 | 1840.0 | 1637.0 | 817.0 | 2.0 | 0.0 | 361.0 |
| 2032-01-01 | 32 | 4058.0 | 143.0 | 6.0 | 1488.0 | 0.003665 | 0.0 | 1840.0 | 1637.0 | 816.0 | 0.0 | 0.0 | 363.0 |
| 2033-01-01 | 33 | 4157.0 | 143.0 | 4.0 | 1489.0 | 0.002443 | 0.0 | 1840.0 | 1636.0 | 816.0 | 1.0 | 0.0 | 363.0 |
| 2034-01-01 | 34 | 4095.0 | 143.0 | 2.0 | 1489.0 | 0.001222 | 0.0 | 1840.0 | 1634.0 | 815.0 | 2.0 | 0.0 | 364.0 |
| 2035-01-01 | 35 | 4153.0 | 143.0 | 1.0 | 1490.0 | 0.000612 | 0.0 | 1840.0 | 1634.0 | 815.0 | 0.0 | 0.0 | 366.0 |
| 2036-01-01 | 36 | 4126.0 | 142.0 | 1.0 | 1490.0 | 0.000612 | 1.0 | 1841.0 | 1633.0 | 815.0 | 1.0 | 0.0 | 366.0 |
| 2037-01-01 | 37 | 4130.0 | 142.0 | 1.0 | 1490.0 | 0.000612 | 0.0 | 1841.0 | 1633.0 | 814.0 | 0.0 | 0.0 | 367.0 |
| 2038-01-01 | 38 | 4068.0 | 142.0 | 1.0 | 1490.0 | 0.000612 | 0.0 | 1841.0 | 1633.0 | 814.0 | 0.0 | 0.0 | 367.0 |
| 2039-01-01 | 39 | 4098.0 | 142.0 | 1.0 | 1490.0 | 0.000612 | 0.0 | 1841.0 | 1633.0 | 814.0 | 0.0 | 0.0 | 367.0 |
| 2040-01-01 | 40 | 4008.0 | 142.0 | 1.0 | 1490.0 | 0.000612 | 0.0 | 1841.0 | 1633.0 | 814.0 | 0.0 | 0.0 | 367.0 |
| 2041-01-01 | 41 | 4045.0 | 142.0 | 1.0 | 1490.0 | 0.000612 | 0.0 | 1841.0 | 1633.0 | 814.0 | 0.0 | 0.0 | 367.0 |
| 2042-01-01 | 42 | 4076.0 | 142.0 | 1.0 | 1490.0 | 0.000612 | 0.0 | 1841.0 | 1633.0 | 814.0 | 0.0 | 0.0 | 367.0 |
| 2043-01-01 | 43 | 4112.0 | 142.0 | 0.0 | 1491.0 | 0.000000 | 0.0 | 1841.0 | 1633.0 | 814.0 | 0.0 | 0.0 | 367.0 |
| 2044-01-01 | 44 | 4037.0 | 142.0 | 0.0 | 1491.0 | 0.000000 | 0.0 | 1841.0 | 1633.0 | 814.0 | 0.0 | 0.0 | 367.0 |
| 2045-01-01 | 45 | 4037.0 | 142.0 | 0.0 | 1491.0 | 0.000000 | 0.0 | 1841.0 | 1633.0 | 814.0 | 0.0 | 0.0 | 367.0 |
| 2046-01-01 | 46 | 4054.0 | 142.0 | 0.0 | 1491.0 | 0.000000 | 0.0 | 1841.0 | 1633.0 | 814.0 | 0.0 | 0.0 | 367.0 |
| 2047-01-01 | 47 | 4033.0 | 142.0 | 0.0 | 1491.0 | 0.000000 | 0.0 | 1841.0 | 1633.0 | 814.0 | 0.0 | 0.0 | 367.0 |
| 2048-01-01 | 48 | 4078.0 | 142.0 | 0.0 | 1491.0 | 0.000000 | 0.0 | 1841.0 | 1633.0 | 814.0 | 0.0 | 0.0 | 367.0 |
| 2049-01-01 | 49 | 4066.0 | 142.0 | 0.0 | 1491.0 | 0.000000 | 0.0 | 1841.0 | 1633.0 | 814.0 | 0.0 | 0.0 | 367.0 |
| 2050-01-01 | 50 | 4160.0 | 142.0 | 0.0 | 1491.0 | 0.000000 | 0.0 | 1841.0 | 1633.0 | 814.0 | 0.0 | 0.0 | 367.0 |
The dataframes in the Samples object are cached, so that the dataframes don’t all need to be loaded in order to start working with the file. The first time a dataframe is accessed, it will be loaded from disk. Subsequent requests for the dataframe will return a cached version instead. The cached dataframe is copied each time it is retrieved, to prevent accidentally modifying the original data.
Common analysis operations
Here are some examples of common analyses that can be performed using functionality in the Samples class
Plotting summary quantities
Often it’s useful to be able plot distributions of summary quantities, such as the total infections. This can be performed by directly indexing the Samples object and then using the appropriate plotting command:
plt.hist(res['cum_infections'], density=True)
plt.xlabel('Total infections')
plt.ylabel('Probability density')Text(0, 0.5, 'Probability density')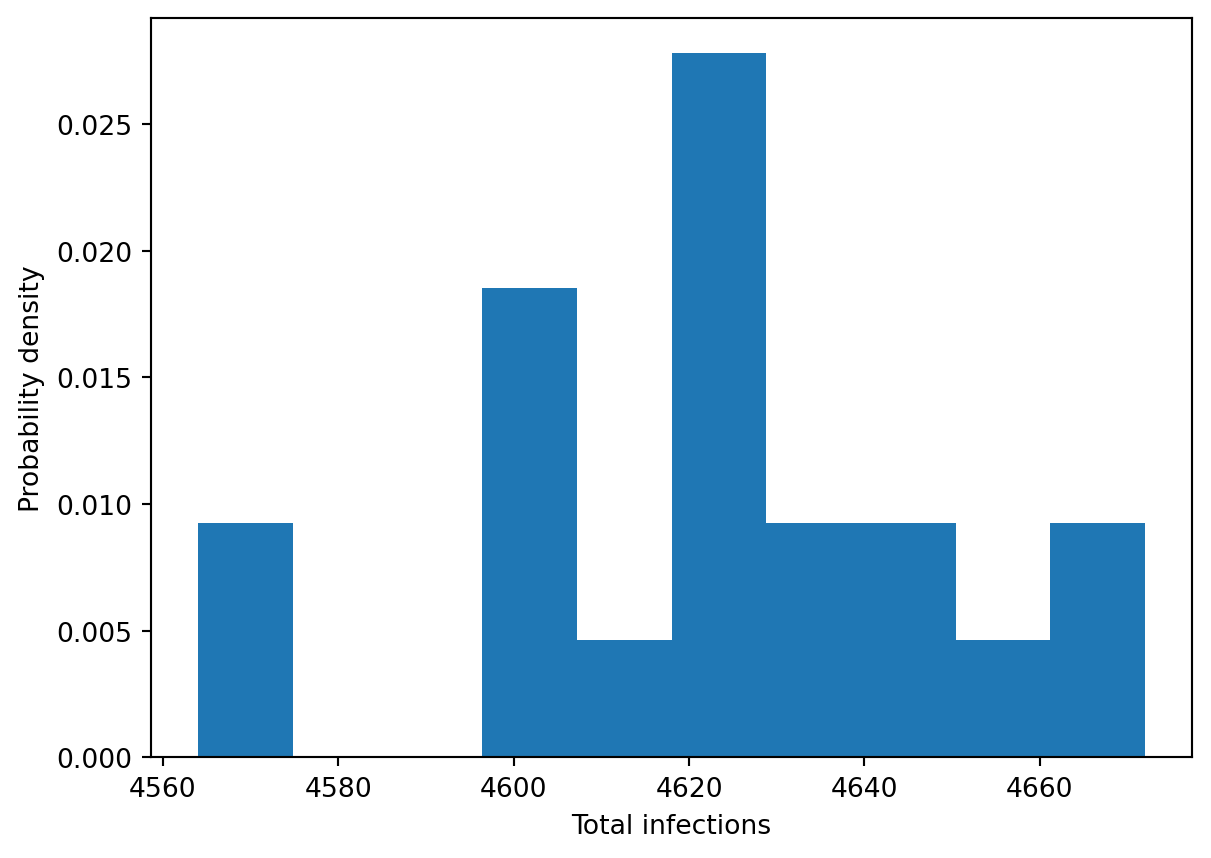
Plotting time series
Time series plots can be obtained by accessing the dataframes associated with each seed, and then plotting quantities from those. For convenience, iterating over the Samples object will automatically iterate over all of the dataframes associated with each seed. For example:
for df in res:
plt.plot(df['sir_new_infections'], color='b', alpha=0.1)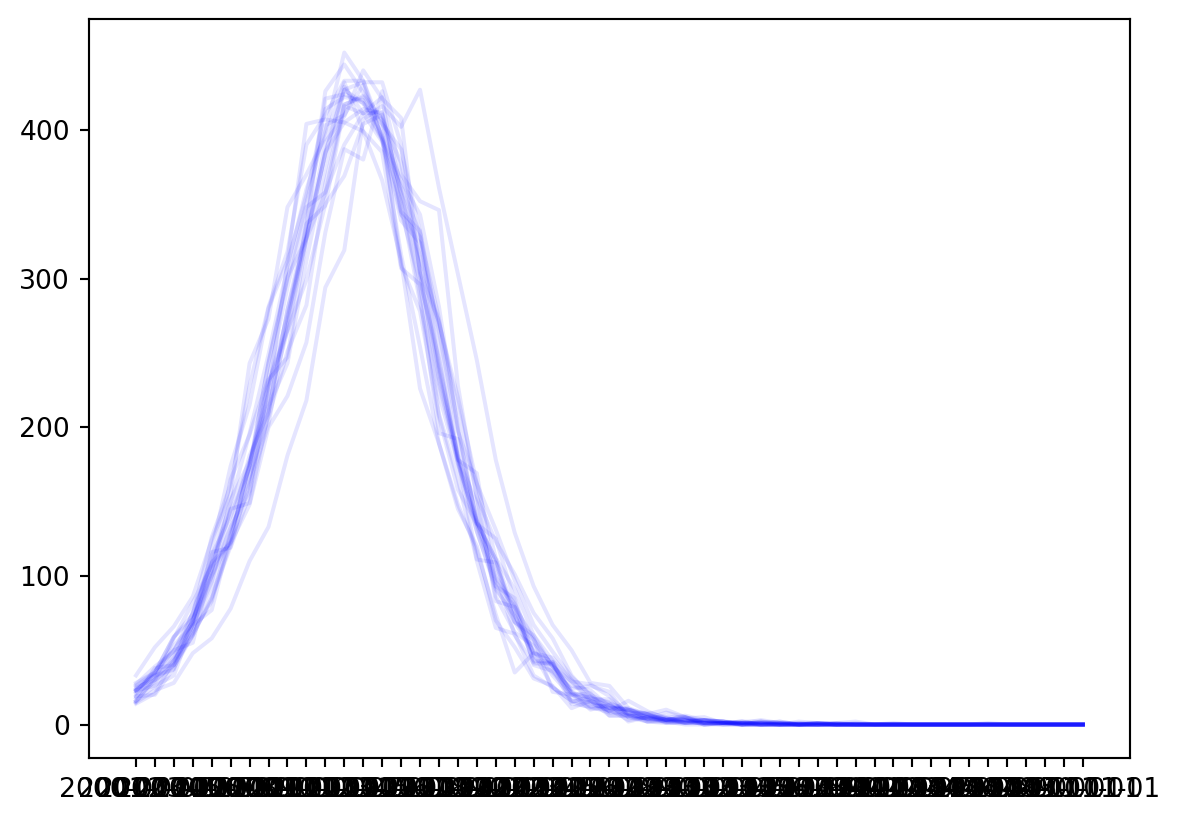
Other ways to access content
We have seen so far that we can use
res.summary- retrieve dataframe of summary outputsres[summary_column]- retrieve a column of the summary dataframeres[seed]- retrieve the time series dataframe associated with one of the simulationsfor df in res- iterate over time series dataframes
Sometimes it is useful to have access to both the summary dictionary and the time series dataframe associated with a single sample. These can be accessed using the get method, which takes in a seed, and returns both outputs for that seed together:
res.get(0) # Retrieve both summary quantities and dataframes(#0. 'p_death': 0.2
#1. 'cum_infections': 1841.0
#2. 'cum_deaths': 367.0,
Unnamed: 0 randomnet_n_edges sir_n_susceptible sir_n_infected \
timevec
2000-01-01 0 5078.0 1977.0 23.0
2001-01-01 1 5008.0 1966.0 34.0
2002-01-01 2 5081.0 1946.0 54.0
2003-01-01 3 4907.0 1927.0 73.0
2004-01-01 4 4939.0 1885.0 115.0
2005-01-01 5 4954.0 1838.0 160.0
2006-01-01 6 5052.0 1780.0 205.0
2007-01-01 7 4958.0 1688.0 286.0
2008-01-01 8 4992.0 1592.0 367.0
2009-01-01 9 4947.0 1477.0 450.0
2010-01-01 10 4984.0 1329.0 570.0
2011-01-01 11 4893.0 1164.0 694.0
2012-01-01 12 4931.0 1008.0 788.0
2013-01-01 13 4977.0 829.0 888.0
2014-01-01 14 4997.0 686.0 937.0
2015-01-01 15 4874.0 539.0 984.0
2016-01-01 16 4819.0 434.0 967.0
2017-01-01 17 4698.0 352.0 896.0
2018-01-01 18 4651.0 294.0 791.0
2019-01-01 19 4633.0 245.0 683.0
2020-01-01 20 4475.0 211.0 553.0
2021-01-01 21 4474.0 186.0 440.0
2022-01-01 22 4385.0 163.0 345.0
2023-01-01 23 4248.0 158.0 244.0
2024-01-01 24 4249.0 153.0 180.0
2025-01-01 25 4162.0 150.0 131.0
2026-01-01 26 4208.0 146.0 89.0
2027-01-01 27 4117.0 145.0 49.0
2028-01-01 28 4066.0 145.0 33.0
2029-01-01 29 4124.0 144.0 21.0
2030-01-01 30 4174.0 143.0 17.0
2031-01-01 31 4100.0 143.0 9.0
2032-01-01 32 4058.0 143.0 6.0
2033-01-01 33 4157.0 143.0 4.0
2034-01-01 34 4095.0 143.0 2.0
2035-01-01 35 4153.0 143.0 1.0
2036-01-01 36 4126.0 142.0 1.0
2037-01-01 37 4130.0 142.0 1.0
2038-01-01 38 4068.0 142.0 1.0
2039-01-01 39 4098.0 142.0 1.0
2040-01-01 40 4008.0 142.0 1.0
2041-01-01 41 4045.0 142.0 1.0
2042-01-01 42 4076.0 142.0 1.0
2043-01-01 43 4112.0 142.0 0.0
2044-01-01 44 4037.0 142.0 0.0
2045-01-01 45 4037.0 142.0 0.0
2046-01-01 46 4054.0 142.0 0.0
2047-01-01 47 4033.0 142.0 0.0
2048-01-01 48 4078.0 142.0 0.0
2049-01-01 49 4066.0 142.0 0.0
2050-01-01 50 4160.0 142.0 0.0
sir_n_recovered sir_prevalence sir_new_infections \
timevec
2000-01-01 0.0 0.011500 6.0
2001-01-01 0.0 0.017000 11.0
2002-01-01 0.0 0.027000 20.0
2003-01-01 0.0 0.036500 19.0
2004-01-01 0.0 0.057500 42.0
2005-01-01 2.0 0.080000 47.0
2006-01-01 15.0 0.102500 58.0
2007-01-01 22.0 0.143000 92.0
2008-01-01 35.0 0.183868 96.0
2009-01-01 58.0 0.225677 115.0
2010-01-01 83.0 0.287154 148.0
2011-01-01 114.0 0.350151 165.0
2012-01-01 166.0 0.399594 156.0
2013-01-01 234.0 0.452599 179.0
2014-01-01 313.0 0.480267 143.0
2015-01-01 396.0 0.508264 147.0
2016-01-01 495.0 0.503908 105.0
2017-01-01 618.0 0.472574 82.0
2018-01-01 746.0 0.423901 58.0
2019-01-01 876.0 0.373020 49.0
2020-01-01 1000.0 0.306541 34.0
2021-01-01 1109.0 0.249433 25.0
2022-01-01 1201.0 0.198847 23.0
2023-01-01 1289.0 0.142774 5.0
2024-01-01 1342.0 0.106446 5.0
2025-01-01 1383.0 0.078209 3.0
2026-01-01 1422.0 0.053486 4.0
2027-01-01 1452.0 0.029572 1.0
2028-01-01 1463.0 0.020049 0.0
2029-01-01 1474.0 0.012797 1.0
2030-01-01 1479.0 0.010372 1.0
2031-01-01 1485.0 0.005491 0.0
2032-01-01 1488.0 0.003665 0.0
2033-01-01 1489.0 0.002443 0.0
2034-01-01 1489.0 0.001222 0.0
2035-01-01 1490.0 0.000612 0.0
2036-01-01 1490.0 0.000612 1.0
2037-01-01 1490.0 0.000612 0.0
2038-01-01 1490.0 0.000612 0.0
2039-01-01 1490.0 0.000612 0.0
2040-01-01 1490.0 0.000612 0.0
2041-01-01 1490.0 0.000612 0.0
2042-01-01 1490.0 0.000612 0.0
2043-01-01 1491.0 0.000000 0.0
2044-01-01 1491.0 0.000000 0.0
2045-01-01 1491.0 0.000000 0.0
2046-01-01 1491.0 0.000000 0.0
2047-01-01 1491.0 0.000000 0.0
2048-01-01 1491.0 0.000000 0.0
2049-01-01 1491.0 0.000000 0.0
2050-01-01 1491.0 0.000000 0.0
sir_cum_infections n_alive n_female new_deaths new_emigrants \
timevec
2000-01-01 6.0 2000.0 996.0 0.0 0.0
2001-01-01 17.0 2000.0 996.0 0.0 0.0
2002-01-01 37.0 2000.0 996.0 0.0 0.0
2003-01-01 56.0 2000.0 996.0 0.0 0.0
2004-01-01 98.0 2000.0 996.0 0.0 0.0
2005-01-01 145.0 2000.0 996.0 0.0 0.0
2006-01-01 203.0 2000.0 996.0 0.0 0.0
2007-01-01 295.0 1996.0 996.0 4.0 0.0
2008-01-01 391.0 1994.0 994.0 2.0 0.0
2009-01-01 506.0 1985.0 994.0 9.0 0.0
2010-01-01 654.0 1982.0 992.0 3.0 0.0
2011-01-01 819.0 1972.0 991.0 10.0 0.0
2012-01-01 975.0 1962.0 987.0 10.0 0.0
2013-01-01 1154.0 1951.0 983.0 11.0 0.0
2014-01-01 1297.0 1936.0 979.0 15.0 0.0
2015-01-01 1444.0 1919.0 976.0 17.0 0.0
2016-01-01 1549.0 1896.0 969.0 23.0 0.0
2017-01-01 1631.0 1866.0 958.0 30.0 0.0
2018-01-01 1689.0 1831.0 939.0 35.0 0.0
2019-01-01 1738.0 1804.0 916.0 27.0 0.0
2020-01-01 1772.0 1764.0 901.0 40.0 0.0
2021-01-01 1797.0 1735.0 879.0 29.0 0.0
2022-01-01 1820.0 1709.0 861.0 26.0 0.0
2023-01-01 1825.0 1691.0 846.0 18.0 0.0
2024-01-01 1830.0 1675.0 840.0 16.0 0.0
2025-01-01 1833.0 1664.0 832.0 11.0 0.0
2026-01-01 1837.0 1657.0 827.0 7.0 0.0
2027-01-01 1838.0 1646.0 824.0 11.0 0.0
2028-01-01 1838.0 1641.0 822.0 5.0 0.0
2029-01-01 1839.0 1639.0 819.0 2.0 0.0
2030-01-01 1840.0 1639.0 817.0 0.0 0.0
2031-01-01 1840.0 1637.0 817.0 2.0 0.0
2032-01-01 1840.0 1637.0 816.0 0.0 0.0
2033-01-01 1840.0 1636.0 816.0 1.0 0.0
2034-01-01 1840.0 1634.0 815.0 2.0 0.0
2035-01-01 1840.0 1634.0 815.0 0.0 0.0
2036-01-01 1841.0 1633.0 815.0 1.0 0.0
2037-01-01 1841.0 1633.0 814.0 0.0 0.0
2038-01-01 1841.0 1633.0 814.0 0.0 0.0
2039-01-01 1841.0 1633.0 814.0 0.0 0.0
2040-01-01 1841.0 1633.0 814.0 0.0 0.0
2041-01-01 1841.0 1633.0 814.0 0.0 0.0
2042-01-01 1841.0 1633.0 814.0 0.0 0.0
2043-01-01 1841.0 1633.0 814.0 0.0 0.0
2044-01-01 1841.0 1633.0 814.0 0.0 0.0
2045-01-01 1841.0 1633.0 814.0 0.0 0.0
2046-01-01 1841.0 1633.0 814.0 0.0 0.0
2047-01-01 1841.0 1633.0 814.0 0.0 0.0
2048-01-01 1841.0 1633.0 814.0 0.0 0.0
2049-01-01 1841.0 1633.0 814.0 0.0 0.0
2050-01-01 1841.0 1633.0 814.0 0.0 0.0
cum_deaths
timevec
2000-01-01 0.0
2001-01-01 0.0
2002-01-01 0.0
2003-01-01 0.0
2004-01-01 0.0
2005-01-01 0.0
2006-01-01 0.0
2007-01-01 0.0
2008-01-01 4.0
2009-01-01 6.0
2010-01-01 15.0
2011-01-01 18.0
2012-01-01 28.0
2013-01-01 38.0
2014-01-01 49.0
2015-01-01 64.0
2016-01-01 81.0
2017-01-01 104.0
2018-01-01 134.0
2019-01-01 169.0
2020-01-01 196.0
2021-01-01 236.0
2022-01-01 265.0
2023-01-01 291.0
2024-01-01 309.0
2025-01-01 325.0
2026-01-01 336.0
2027-01-01 343.0
2028-01-01 354.0
2029-01-01 359.0
2030-01-01 361.0
2031-01-01 361.0
2032-01-01 363.0
2033-01-01 363.0
2034-01-01 364.0
2035-01-01 366.0
2036-01-01 366.0
2037-01-01 367.0
2038-01-01 367.0
2039-01-01 367.0
2040-01-01 367.0
2041-01-01 367.0
2042-01-01 367.0
2043-01-01 367.0
2044-01-01 367.0
2045-01-01 367.0
2046-01-01 367.0
2047-01-01 367.0
2048-01-01 367.0
2049-01-01 367.0
2050-01-01 367.0 )In the same way that it is possible to index the Samples object directly in order to retrieve columns from the summary dataframe, it is also possible to directly index the Samples object to get a column of the time series dataframe. In this case, pass a tuple of items to the Samples object, where the first item is the seed, and the second is a column from the time series dataframe. For example:
res[0,'sir_n_infected'] # Equivalent to `res[0]['sir.n_infected']`timevec
2000-01-01 23.0
2001-01-01 34.0
2002-01-01 54.0
2003-01-01 73.0
2004-01-01 115.0
2005-01-01 160.0
2006-01-01 205.0
2007-01-01 286.0
2008-01-01 367.0
2009-01-01 450.0
2010-01-01 570.0
2011-01-01 694.0
2012-01-01 788.0
2013-01-01 888.0
2014-01-01 937.0
2015-01-01 984.0
2016-01-01 967.0
2017-01-01 896.0
2018-01-01 791.0
2019-01-01 683.0
2020-01-01 553.0
2021-01-01 440.0
2022-01-01 345.0
2023-01-01 244.0
2024-01-01 180.0
2025-01-01 131.0
2026-01-01 89.0
2027-01-01 49.0
2028-01-01 33.0
2029-01-01 21.0
2030-01-01 17.0
2031-01-01 9.0
2032-01-01 6.0
2033-01-01 4.0
2034-01-01 2.0
2035-01-01 1.0
2036-01-01 1.0
2037-01-01 1.0
2038-01-01 1.0
2039-01-01 1.0
2040-01-01 1.0
2041-01-01 1.0
2042-01-01 1.0
2043-01-01 0.0
2044-01-01 0.0
2045-01-01 0.0
2046-01-01 0.0
2047-01-01 0.0
2048-01-01 0.0
2049-01-01 0.0
2050-01-01 0.0
Name: sir_n_infected, dtype: float64Filtering results
The .seeds attribute contains a listing of seeds, which can be helpful for iteration:
res.seedsarray([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19])The seeds are drawn from the summary dataframe, which defines which seeds are accessible via the Samples object. Therefore, you can drop rows from the summary dataframe to filter the results. For example, suppose we only wanted to analyze simulations with over 4900 deaths. We could retrieve a copy of the summary dataframe that only contains matching simulations:
res.summary.loc[res['cum_infections']>4900]| cum_infections | cum_deaths | ||
|---|---|---|---|
| seed | p_death |
We can then make a copy of the results and write the reduced summary dataframe back to that object:
res2 = res.copy()
res2.summary = res.summary.loc[res['cum_infections']>4900]
Unlike
sc.dcp(), copying using the .copy() method only deep copies the summary dataframe. It does not duplicate the time series dataframes or the cache. For Samples objects, it is therefore generally preferable to use .copy().
Now notice that there are fewer samples, and the seeds have been filtered:
len(res)20len(res2)0res2.seedsarray([], dtype=int64)plt.hist(res2['cum_infections'], density=True)
plt.xlabel('Total infections')
plt.ylabel('Probability density')/opt/hostedtoolcache/Python/3.13.14/x64/lib/python3.13/site-packages/numpy/lib/_histograms_impl.py:897: RuntimeWarning: invalid value encountered in divide
return n / db / n.sum(), bin_edgesText(0, 0.5, 'Probability density')
Applying functions and transformations
Sometimes it might be necessary to calculate quantities that are derived from the time series dataframes. These could be simple scalar values, such as totals or averages that had not been computed ahead of time, or extracting values from each simulation at a particular point in time. As an alternative to writing a loop that iterates over the seeds, the .apply() method takes in a function and maps it to every dataframe. This makes it quick to construct lists or arrays with scalar values extracted from the time series. For example, suppose we wanted to extract the peak number of people infected from each simulation:
peak_infections = lambda df: df['sir_n_infected'].max()
res.apply(peak_infections)[984.0,
947.0,
995.0,
1015.0,
967.0,
973.0,
1047.0,
1014.0,
975.0,
950.0,
934.0,
1013.0,
1025.0,
983.0,
980.0,
993.0,
946.0,
1012.0,
901.0,
992.0]Options when loading
There are two options available when loading that can change how the Samples class interacts with the file on disk:
memory_buffer- copy the entire file into memory. This prevents the file from being locked on disk and allows scripts to be re-run and results regenerated while still running the analysis notebook. This defaults toTruefor convenience, but loading the entire file into memory can be problematic if the file is large (e.g., >1GB) in which case settingmemory_buffer=Falsemay be preferablepreload- Populate the cache in one step. This facilitates interactive usage of the analysis notebook by making the runtime of analysis functions predictable (since all results will be retrieved from the cache) at the expense of a long initial load time
Implementation details
If the file is loaded from a memory buffer, the ._zipfile attribute will be populated. A helper property .zipfile is used to access the buffer, so if caching is not used, .zipfile returns the actual file on disk rather than the buffer:
res = ss.Samples('results/0.2.zip', memory_buffer=True) # Copy the entire file into memory
print(res._zipfile)
print(res.zipfile)<zipfile.ZipFile file=<_io.BytesIO object at 0x7ff099d1ba60> mode='r'>
<zipfile.ZipFile file=<_io.BytesIO object at 0x7ff099d1ba60> mode='r'>res = ss.Samples('results/0.2.zip', memory_buffer=False) # Copy the entire file into memory
print(res._zipfile)
print(res.zipfile)<zipfile.ZipFile filename='results/0.2.zip' mode='r'>
<zipfile.ZipFile filename='results/0.2.zip' mode='r'>The dataframes associated with the individual dataframes are cached on access, so pd.read_csv() only needs to be called once. The cache starts out empty:
res._cache{}When a dataframe is accessed, it is automatically stored in the cache:
res[0]
res._cache.keys()dict_keys([0])This means that iterating through the dataframes the first time can be slow (but in general, iterating over all dataframes is avoided in favour of either only using summary outputs, or accessing a subset of the runs):
with sc.Timer():
for df in res:
continueElapsed time: 27.7 mswith sc.Timer():
for df in res:
continueElapsed time: 6.37 msThe preload option populates the entire cache in advance. This makes creating the Samples object slower, but operating on the dataframes afterwards will be consistently fast. This type of usage can be useful when wanting to load large files in the background and then interactively work with them afterwards.
with sc.Timer():
res = ss.Samples('results/0.2.zip', preload=True)Elapsed time: 29.8 mswith sc.Timer():
for df in res:
continueElapsed time: 5.48 mswith sc.Timer():
for df in res:
continueElapsed time: 6.73 msTogether, these options provide some flexibility in terms of memory and time demands to suit analyses at various different scales.
Running scenarios
Suppose we wanted to compare a range of different p_death values and initial values (initial number of infections). We might define these runs as:
initials = np.arange(1,4)
p_deaths = np.arange(0,1,0.25)Recall that our run_sim() function had an argument for p_death. We can extend this to include the initial parameter too. We can actually generalize this further by passing the parameters as keyword arguments to avoid needing to hard-code all of them. Note that we also need to add the initial value to the summary outputs:
def get_sim(seed, **kwargs):
ppl = ss.People(1000)
net = ss.RandomNet(n_contacts=ss.poisson(5))
sir = ss.SIR(pars=kwargs)
sim = ss.Sim(people=ppl, networks=net, diseases=sir, rand_seed=seed, dur=ss.years(10))
sim.init(verbose=0)
return sim
def run_sim(seed, **kwargs):
sim = get_sim(seed, **kwargs)
sim.run(verbose=0)
df = sim.to_df()
sir = sim.diseases.sir
summary = {}
summary['seed'] = sim.pars.rand_seed
summary['p_death']= sir.pars.p_death.pars.p
summary['initial']= sir.pars.init_prev.pars.p
summary['cum_infections'] = sum(sim.results.sir.new_infections)
summary['cum_deaths'] = sum(sim.results.new_deaths)
return df, summaryWe can now easily run a set of scenarios with different values of p_death and save each one to a separate Samples object. Note that when we create the Samples objects now, we also want to specify that 'init_prev' is one of the identifiers for the scenarios:
# Clear the existing results
for file_path in resultsdir.glob('*'):
file_path.unlink()# Run the sweep over initial and p_death
n = 5
seeds = np.arange(n)
for init_prev in initials:
for p_death in p_deaths:
outputs = [run_sim(seed, init_prev=init_prev, p_death=p_death) for seed in seeds]
ss.Samples.new(outputs, identifiers=["p_death", "initial"], folder=resultsdir)Zip file saved to "/home/runner/work/starsim/starsim/docs/user_guide/results/0.0-1.zip"
Zip file saved to "/home/runner/work/starsim/starsim/docs/user_guide/results/0.25-1.zip"
Zip file saved to "/home/runner/work/starsim/starsim/docs/user_guide/results/0.5-1.zip"
Zip file saved to "/home/runner/work/starsim/starsim/docs/user_guide/results/0.75-1.zip"
Zip file saved to "/home/runner/work/starsim/starsim/docs/user_guide/results/0.0-2.zip"
Zip file saved to "/home/runner/work/starsim/starsim/docs/user_guide/results/0.25-2.zip"
Zip file saved to "/home/runner/work/starsim/starsim/docs/user_guide/results/0.5-2.zip"
Zip file saved to "/home/runner/work/starsim/starsim/docs/user_guide/results/0.75-2.zip"
Zip file saved to "/home/runner/work/starsim/starsim/docs/user_guide/results/0.0-3.zip"
Zip file saved to "/home/runner/work/starsim/starsim/docs/user_guide/results/0.25-3.zip"
Zip file saved to "/home/runner/work/starsim/starsim/docs/user_guide/results/0.5-3.zip"
Zip file saved to "/home/runner/work/starsim/starsim/docs/user_guide/results/0.75-3.zip"The results folder now contains a collection of saved Samples objects. Notice how the automatically selected file names now contain both the p_death value and the initial value, because they were both specified as identifiers. We can load one of these objects in to see how these identifiers are stored and accessed inside the Samples class:
list(resultsdir.iterdir())[PosixPath('results/0.75-2.zip'),
PosixPath('results/0.5-1.zip'),
PosixPath('results/0.5-3.zip'),
PosixPath('results/0.0-3.zip'),
PosixPath('results/0.75-3.zip'),
PosixPath('results/0.25-1.zip'),
PosixPath('results/0.0-1.zip'),
PosixPath('results/0.75-1.zip'),
PosixPath('results/0.5-2.zip'),
PosixPath('results/0.25-2.zip'),
PosixPath('results/0.25-3.zip'),
PosixPath('results/0.0-2.zip')]res = ss.Samples('results/0.25-2.zip')The ‘id’ of a Samples object is a dictionary of the identifiers, which makes it easy to access the input parameters associated with a set of scenario runs:
res.id{'p_death': 0.25, 'initial': 2}The ‘identifier’ is a tuple of these values, which is suitable for use as a dictionary key. This can be useful for accumulating and comparing variables across scenarios:
res.identifier(0.25, 2)Loading multiple scenarios
We saw above that we now have a directory full of .zip files corresponding to the various scenario runs. These can be accessed using the Dataset class, which facilitates accessing multiple instances of Samples. We can pass the folder containing the results to the Dataset constructor to load them all:
results = ss.Dataset(resultsdir)
results<Dataset:
'p_death':[0.0, 0.25, 0.5, 0.75]
'initial':[1, 2, 3]
>The .ids attribute lists all of the values available across scenarios in the results folder:
results.ids{'p_death': [0.0, 0.25, 0.5, 0.75], 'initial': [1, 2, 3]}The individual results can be accessed by indexing the Dataset instance using the values of the identifiers. For example:
results[0.25,2]<Samples 0.25-2, 5 seeds>This indexing operation is sensitive to the order in which the identifiers are specified. The .get() method allows you to specify them as key-value pairs:
results.get(initial=2, p_death=0.25)<Samples 0.25-2, 5 seeds>Iterating over the Dataset will iterate over the Samples instances contained within it:
for res in results:
print(res)<Samples 0.0-1, 5 seeds>
<Samples 0.0-2, 5 seeds>
<Samples 0.0-3, 5 seeds>
<Samples 0.25-1, 5 seeds>
<Samples 0.25-2, 5 seeds>
<Samples 0.25-3, 5 seeds>
<Samples 0.5-1, 5 seeds>
<Samples 0.5-2, 5 seeds>
<Samples 0.5-3, 5 seeds>
<Samples 0.75-1, 5 seeds>
<Samples 0.75-2, 5 seeds>
<Samples 0.75-3, 5 seeds>This can be used to extract and compare values across scenarios. For example, we could consider the use case of making a plot that compares total deaths across scenarios:
labels = []
y = []
yerr = []
for res in results:
labels.append(res.id)
y.append(res['cum_deaths'].median())
plt.barh(np.arange(len(results)),y, tick_label=labels)
plt.xlabel('Median total deaths');
plt.ylabel('Scenario')Text(0, 0.5, 'Scenario')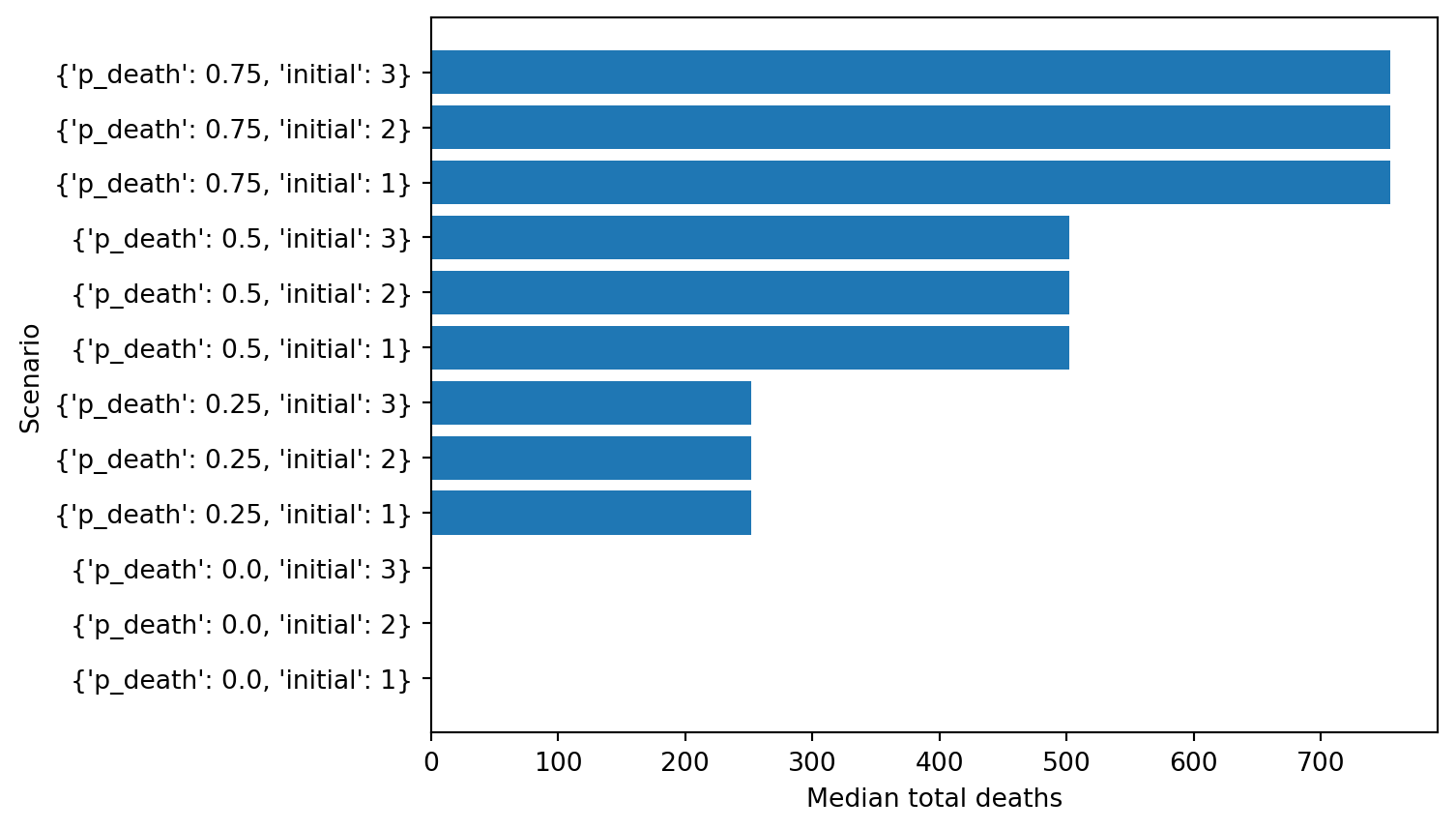
Filtering scenarios
Often plots need to be generated for a subset of scenarios e.g., for sensitivity analysis or to otherwise compare specific scenarios. Dataset.filter returns a new Dataset containing a subset of the results:
for res in results.filter(initial=2):
print(res)<Samples 0.0-2, 5 seeds>
<Samples 0.25-2, 5 seeds>
<Samples 0.5-2, 5 seeds>
<Samples 0.75-2, 5 seeds>for res in results.filter(p_death=0.25):
print(res)<Samples 0.25-1, 5 seeds>
<Samples 0.25-2, 5 seeds>
<Samples 0.25-3, 5 seeds>This is also a quick and efficient operation, so you can easily embed filtering commands inside the analysis to select subsets of the scenarios for plotting and other output generation. For instance:
for res, color in zip(results.filter(initial=2), sc.gridcolors(4)):
plt.plot(res[0].index, np.median([df['new_deaths'] for df in res], axis=0), color=color, label=f'p_death = {res.id["p_death"]}')
plt.legend()
plt.title('Sensitivity to p_death (initial = 2)')
plt.xlabel('Year')
plt.ylabel('New deaths')Text(0, 0.5, 'New deaths')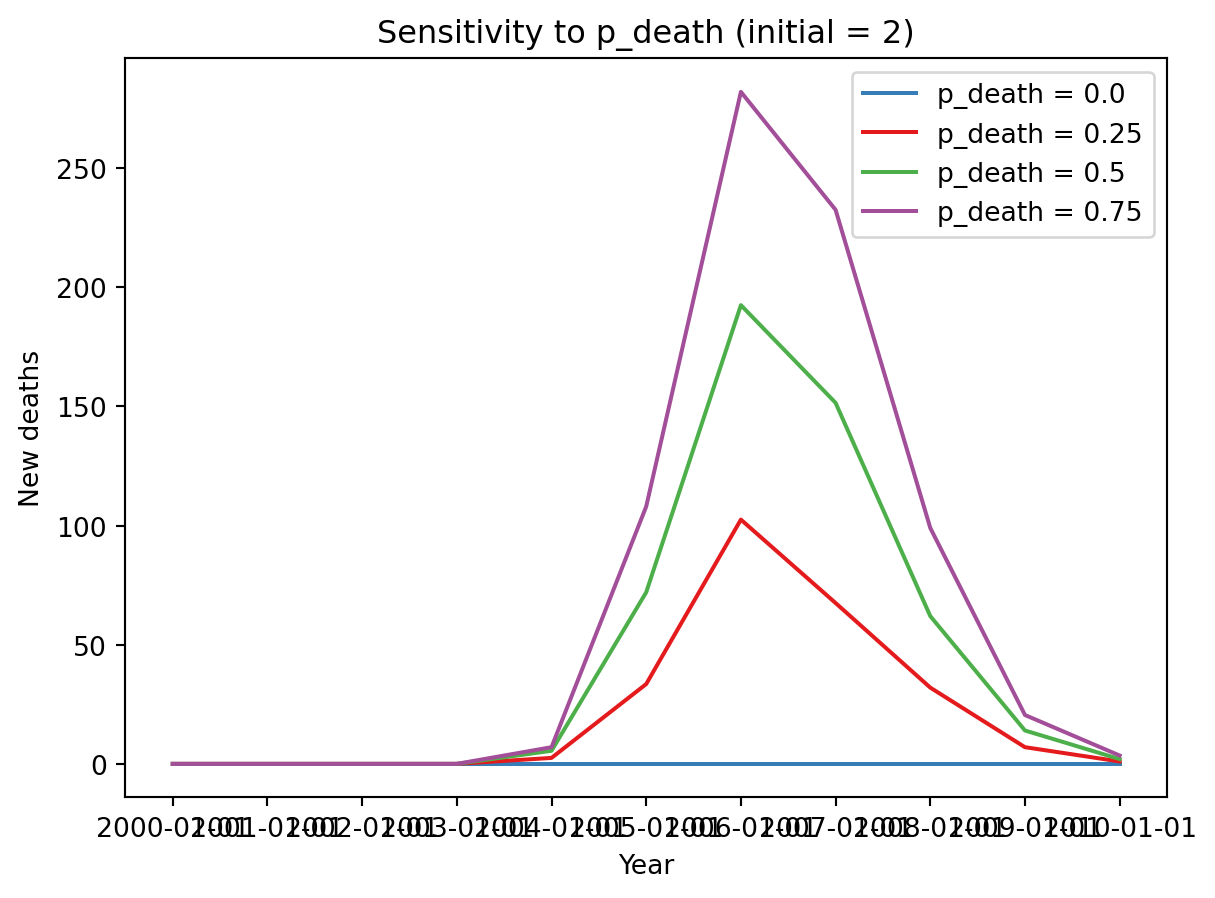
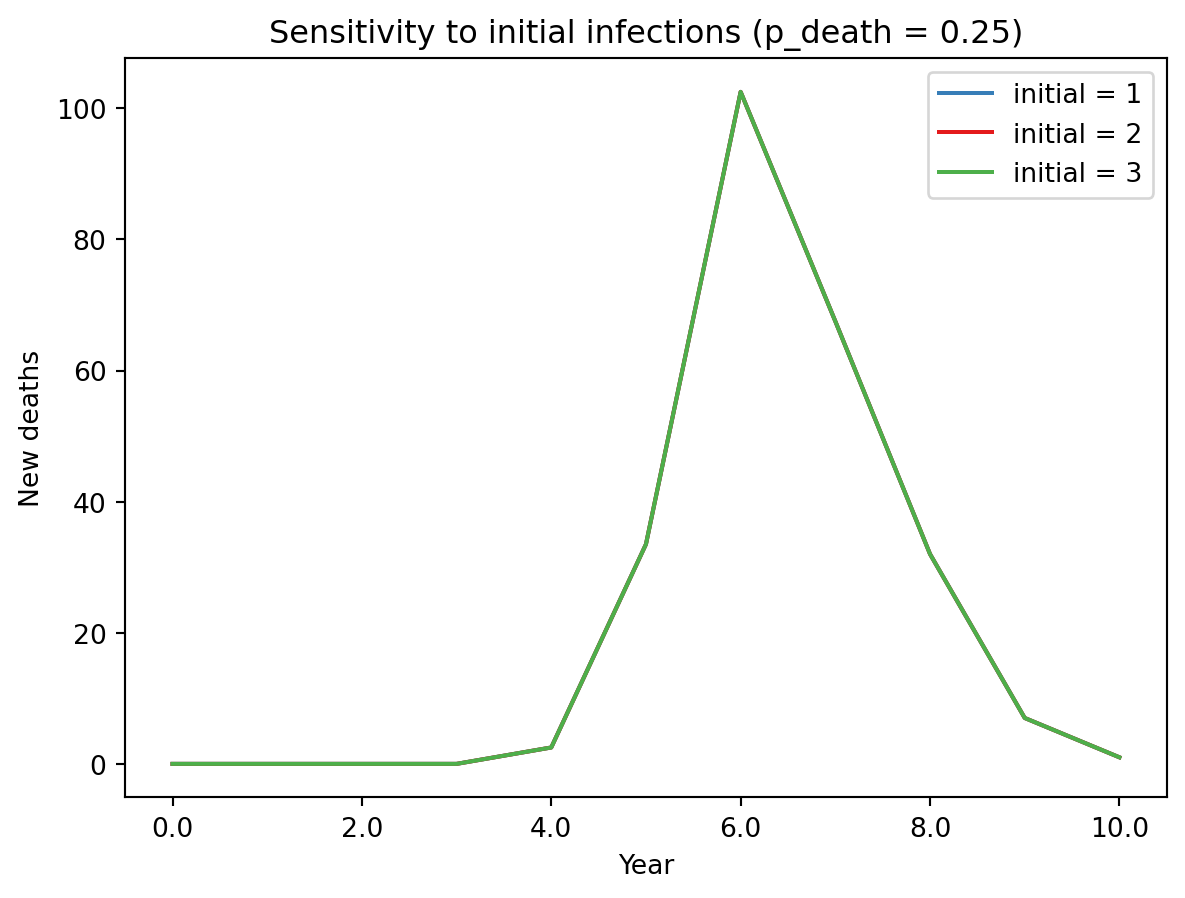
for res, color in zip(results.filter(p_death=0.25), sc.gridcolors(3)):
plt.plot(res[0].index, np.median([df['new_deaths'] for df in res], axis=0), color=color, label=f'initial = {res.id["initial"]}')
plt.legend()
plt.title('Sensitivity to initial infections (p_death = 0.25)')
plt.xlabel('Year')
plt.ylabel('New deaths')
sc.dateformatter()/opt/hostedtoolcache/Python/3.13.14/x64/lib/python3.13/site-packages/matplotlib/axis.py:1345: RuntimeWarning: Axes data not recognizable as dates: Matplotlib converted them to days starting in 1970, which seems wrong. Please convert to actual dates first, using e.g. sc.date().
Raw values: [0.00000000e+00 2.31481481e-11 4.62962963e-11 6.94444444e-11
9.25925926e-11 1.15740741e-10]
major_labels = self.major.formatter.format_ticks(major_locs)